
Inversión de Dependencias vs Inyección de Dependencias vs Inversión de Control
Inversión de dependencias, inyección de dependencias, inversión de control… ¿Te suenan estos conceptos? ¿Conoces sus diferencias? Hoy intentaré explicar estos conceptos aclarando dónde empieza y dónde termina cada uno y porqué son confundidos en muchas ocasiones.
Principio de Inversión de la Dependencia (DIP)
El Principio de Inversión de la Dependencia (Dependency Inversion Principle, DIP) es uno de los cinco principios que componen SOLID (Single responsibility, Open-closed, Liskov substitution, Interface segregation and Dependency inversion). Estos principios son considerados los pilares básicos de la programación orientada a objetos que todo desarrollador debería conocer para conseguir sistemas de calidad, reutilizables, tolerantes al cambio, desacoplados y testeables.
Hay mucha información por la red en torno a este concepto, así que para aislarnos de las posibles interpretaciones personales nos basaremos en la idea original, que se atribuye a Robert C. Martin y se remonta ni más ni menos que al año 1995. Por aquella época se definió el concepto con las siguientes premisas:
Los módulos de alto nivel no deben depender de los módulos de bajo nivel. Ambos deben depender de abstracciones.
Las abstracciones no deben depender de los detalles. Los detalles deben depender de las abstracciones.
Entender esto así, sin más, puede resultar complicado: ¿a qué se refiere con “módulos de alto y bajo nivel”?, ¿y eso de “abstracciones”?. Vale, ahora sí me permitiré el lujo de hacer algunas interpretaciones personales derivadas de lo anterior con el fin de hacerlo más entendible. Qué tal si, dado que nos movemos dentro del ámbito de la orientación de objetos, sustituimos “módulos de alto nivel” por “clases importantes”. Y desglosamos el término “abstracciones” por “interfaces o clases abstractas”. Con esto podemos llegar a lo siguiente:
- Las clases importantes no deben depender de las clases menos importantes. Ambas deben depender de interfaces o clases abstractas.
Ok, y ¿qué es para ti “importante”? Pues digamos que: depende ;) pero si hablamos de una aplicación empresarial podría decirse que una clase que gestiona las reglas de negocio es más importante (o debería) que una que se encarga de persistir los datos o que otra que se encarga de comunicarse con otros servicios externos. El modo de persistir los datos o el protocolo de comunicación no afecta a mis reglas de negocio, en cambio una modificación en esas reglas si puede afectar a qué datos se deben persistir o con qué servicios me debo comunicar.
Pero si para tí lo importante es, por ejemplo, la estabilidad del código, es decir que tu aplicación sufra lo menos posible ante los cambios, podemos también sustituir “importante” por “estable” y la definición quedaría así:
- Las clases más estables no deben depender de las clases más inestables. Ambas deben depender de interfaces o clases abstractas.
Bueno, parece que vamos allanando terreno, pero ¿qué hay de la segunda premisa? Pues básicamente nos viene a decir que lo primero en lo que hay que pensar es en definir bien las interfaces y a partir de esa especificación construir las clases que lo implementan, y no al contrario.
- Las clases importantes no deben depender de las clases menos importantes. Ambas deben depender de interfaces o clases abstractas.
- Las interfaces y clases abstractas no deben depender de las implementaciones. Las implementaciones deben depender de las interfaces y clases abstractas.
Pero aun así “si no lo veo no lo entiendo”, así que pongamos esto en práctica y llevémoslo a un ejemplo simple pero realista (y también un poco típico): digamos que tenemos una clase ‘Logic’ que realiza una operación como parte de nuestra lógica de negocio y que ésta necesita almacenar el resultado en una base de datos, por ejemplo MySql.
Comparemos la implementación de este ejemplo con programación tradicional y luego aplicando el principio de inversión de dependencias.
Ejemplo tradicional
En una implementación tradicional por un lado tendremos una clase MySqlDatabase que realizará una serie de operaciones sobre la base de datos MySql. Esta clase probablemente dará servicio a numerosas operaciones de nuestra aplicación y será más o menos compleja. Cuando queramos implementar la clase Logic para realizar una nueva operación será ésta la que se adapte al comportamiento de MySqlDatabase, es decir Logic usará y dependerá de MySqlDatabase:
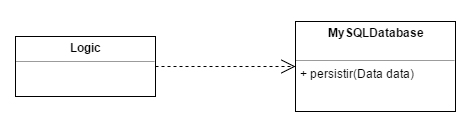
Este podría ser el código:
public class MySqlDatabase {
public void persist(Data data){
// Guarda el dato en una base de datos MySql
}
}
public class Logic {
public void operation(Data input) {
// Manipular el dato
Data output = calculateOutput(input);
// Persistir el resultado
MySqlDatabase db = new MySqlDatabase();
db.persist(output);
}
}
Algunos problemas de este planteamiento son:
Las clases están fuertemente acopladas. Si ahora quiero almacenar el dato en una base de datos PostgreSQL tengo que modificar el código de la clase Logic. Es decir, me veo obligado a hacer cambios en una clase importante y estable, Logic, por culpa de una modificación en una menos estable, el modo de almacenar esos datos.
Dificultad para testear. No puedo probar fácilmente el método ‘operation’ de la clase ‘Logic’ sin hacer uso de la base de datos.
Incita a la mezcla de responsabilidades. Cuando un desarrollador, sobretodo si no tiene demasiada experiencia, deba añadir una nueva funcionalidad no tendrá claro dónde hacerlo y porqué: ¿Quién debe tratar las Excepciones lanzadas por MySQL?
Además, si replicamos este planteamiento en todas las clases de lógica y en todas las clases de servicio llegará un momento en que tengamos todo acoplado a todo, resultando en el típico “código cebolla” donde cualquier mínimo cambio puede resultar traumático.
Ejemplo con inversión de dependencia
Si nos fijamos, la clase ‘Logic’, que realiza la lógica de negocio (importante) lo único que necesita es utilizar los servicios de otra clase para persistir los datos (menos importante), así que a la clase ‘Logic’ en realidad le da igual si estos datos se guardan en MySql, PostgreSql o MongoDB, lo único que le importa es que se guarden.
La mejor manera de hacer que la clase ‘Logic’ no conozca las peculiaridades del servicio de base de datos es usando una interfaz. Las interfaces definen qué es lo que puede hacerse con el servicio, actúan como contratos o protocolos de comunicación. En este caso Logic simplemente usará una interfaz y luego, el sistema de persistencia, estará implementado de una forma u otra según lo que indique dicha interfaz.
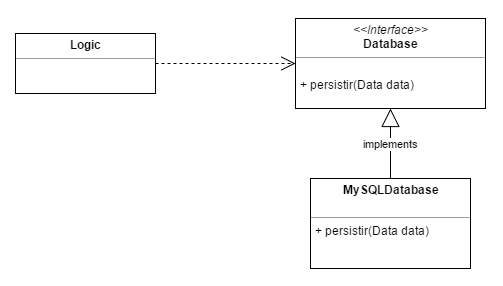
Ahora nuestro código quedará algo así:
public interface Database {
void persist(Data data);
}
public class MySqlDatabase implements Database {
@Override
public void persist(Data data){
// Guarda el dato en una base de datos MySql
}
}
public class Logic {
private final Database database;
public Logic(Database database) {
this.database = database;
}
public void operation(Data input) {
// Manipular el dato
Data output = calculateOutput(input);
// Persistir el resultado
database.persist(output);
}
}
Hemos conseguido que ‘Logic’ ya no dependa de una implementación concreta de ‘Database’. Puede que cambie la base de datos o el API de acceso a datos, pero el concepto de “persistir un dato” es mucho más estable en el tiempo.
Pero ¿hemos invertido la dependencia? Bueno, se invertirá si es Logic quien define la interfaz. Es decir, Logic, que es la clase importante, es quién dice qué es lo que necesita de un servicio de persistencia, es el cliente del contrato. Y luego MySqlDatabase es el proveedor de ese servicio y tendrá que hacer las cosas según esté especificado en ese contrato, llamado en este caso Database. Poco a poco mi lógica de negocio crecerá y mis requisitos de persistencia también, así que iré ampliando el contrato y si el día de mañana resulta que el señor MySqlDatabase no puede cumplir mis expectativas siempre podré invitar a PostgreSqlDatabase, OracleDatabase, o incluso MongoDbDatabase y ver qué tal se comportan. Y todo ello sin modificar mis clases de lógica.
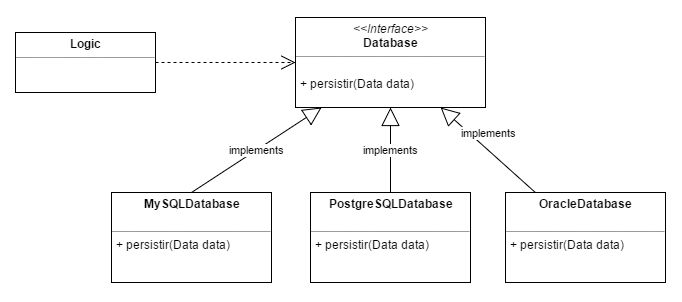
Y aún podríamos elevar un grado más nuestro diseño haciendo que ambas partes dependiesen de abstracciones (que es lo que originalmente propone este principio). De esta manera nuestro sistema estaría preparado para que distintos clientes de un mismo tipo usasen un servicio sin preocuparse de quién es su proveedor.
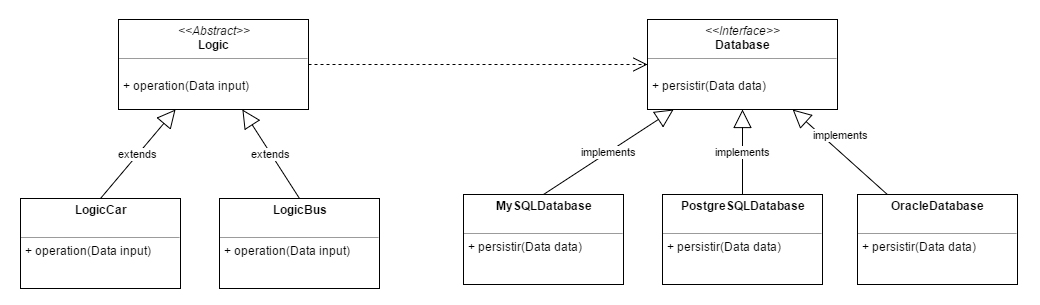
Pero, como habrás observado, ahora la implementación concreta de Database es recibida por constructor. Es decir, se necesita de un tercero que le diga a la clase Logic cuál es la implementación de Database que tiene que usar. ¿Quién se encarga de la creación de esa implementación?
Inyección de Dependencias (DI)
La Inyección de Dependencias (Dependency Injection, DI) es un mecanismo que se encarga de extraer la responsabilidad de creación de instancias de un componente para delegarla en otro. En definitiva no deja de ser una técnica más para separar la construcción de la ejecución.
Existen varias técnicas para tratar los problemas de construcción de objetos. La primera y más obvia es que sea la propia aplicación quien se encargue de esa tarea actuando como controlador (por ejemplo en el método Main). Otra opción es usar algún patrón de diseño creacional como Builder o Abstract Factory. En algunos sitios se menciona también al patrón Service Locator. Bien, pues la Inyección de Dependencias es un patrón más avanzado que éstos donde se delega la función de construcción a un módulo independiente llamado contenedor de inyección de dependencias, el cual se encargará de instanciar todos los objetos y setear las dependencias entre ellos (“cablear” instancias) sin que los propios objetos sepan siquiera que existe dicho contenedor. Es más, ni siquiera la propia aplicación tendrá que preocuparse de ese contenedor.
Un ejemplo ilustrativo de contenedor (muy lejos de la realidad) podría ser el siguiente:
public class InjectContainer {
private Map<String, Object> objects;
public init() {
...
Database db = new MySqlDatabase();
Logic logic = new LogicCar(db);
objects = new HashMap<String, Object>();
objects.put("logic", logic);
...
}
}
Ahora la aplicación podrá solicitar al contenedor el objeto Logic que necesita, lo único que debe saber es su nombre: ‘logic’.
Bien, pero ¿cómo sabe el contenedor que mi aplicación requiere la inyección de MySqlDatabase en LogicCar y no un OracleDatabase en un LogicBus? Esto se resuelve a través de configuración. Podemos tener, por ejemplo, un fichero XML donde le indiquemos estas dependencias. El contenedor de inyección lo leerá y actuará en consecuencia.
Por ejemplo podríamos tener algo como esto:
<configInjectContainer>
<bean>
<name>logic</name>
<type>LogicCar</type>
<inject>MySqlDatabase</inject>
<bean>
</configInjectContainer>
El contenedor se ejecutará junto con mi aplicación, leerá el fichero XML de configuración, instanciará los objetos necesarios usando Reflection, inyectará las dependencias y le ofrecerá esos objetos a mi aplicación a través de una HashMap.
Los contenedores reales, como CDI o Spring, pueden ser configurados con archivos XML o con anotaciones en las propias clases implicadas. Además están preparados para controlar más cosas aparte de la creación e inyección de instancias.
Inversión de Control (IoC)
La Inversión de Control (Inversion of Control, IoC) se refiere a que la aplicación delega algún tipo de flujo de control en un tercero, generalmente un framework. El framework se encargará de gestionar el ciclo de vida de la aplicación e irá notificando eventos a la propia aplicación para que ésta actúe en consecuencia.
Mejor con un ejemplo ;) Supongamos que tenemos una aplicación que se encarga de dar de alta un usuario. Esta aplicación solicitará los datos por consola, los validará y finalmente los almacenará.
...
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
System.out.print("Enter Name: ");
String name = br.readLine();
System.out.print("Enter Login: ");
String login = br.readLine();
System.out.print("Enter Password: ");
String pwd = br.readLine();
validateUser(name, login, pwd);
persistUser(name, login, pwd);
...
En este ejemplo mi aplicación tiene todo el control: decide cuándo pedir los datos, cuando leer las respuestas y cuando procesar los datos.
Ahora imaginemos que queremos hacer lo mismo pero en vez de pedir los datos por consola usamos un panel gráfico de Swing.
...
JTextField nameField = new JTextField(25);
JTextField loginField = new JTextField(25);
JTextField pwdField = new JTextField(25);
...
JButton okButton = new JButton("Aceptar");
okButton.addActionListener(new ActionListener() {
@Override
public void actionPerformed(ActionEvent e) {
String name = nameField.getText();
String login = nameField.getText();
String pwd = nameField.getText();
validateUser(name, login, pwd);
persistUser(name, login, pwd);
}
});
...
JPanel myPanel = new JPanel();
myPanel.add(new JLabel("Enter Name: "));
myPanel.add(nameField);
myPanel.add(new JLabel("Enter Login: "));
myPanel.add(loginField);
myPanel.add(new JLabel("Enter Password: "));
myPanel.add(pwdField);
myPanel.add(okButton);
...
Ahora el flujo de control no lo tiene mi aplicación. La aplicación inicializa un panel gráfico, declara un método que hace de callback y entrega el control al sistema de ventanas, el cual invocará a mi método cuando el usuario pulse el botón “Aceptar”. Hemos invertido el control delegándolo a una pantalla gráfica. Es decir, acabamos de hacer IoC.
IoC, también conocido como el Principio de Hollywood (“No nos llame, ya le llamaremos nosotros”), es una de las principales características que diferencian un framework de un API. Un framework normalmente se encarga de la coordinación y secuenciación de actividades de la aplicación. En cada acción el framework realiza algún tipo de trabajo y devuelve el control al cliente. En cambio un API no es más que un conjunto de rutinas, protocolos y herramientas que nos facilitan la ejecución de ciertas tareas.
Inversión de Control es un término demasiado genérico. La pregunta es: ¿qué aspecto del control se está invirtiendo? En el ejemplo anterior se está invirtiendo el control gráfico, pero también se podría invertir el control de la persistencia de datos, el control del ámbito de ejecución web (scope)… e incluso el control de la creación de objetos… en cuyo caso estaremos hablando de Inyección de Dependencias. Es decir, DI es una especialización de IoC.
La inversión de control se puede implementar de múltiples maneras. Como ocurría con la inyección de dependencias aquí también podemos hacer uso de diferentes patrones como por ejemplo Observer o Strategy. O podemos usar alguna técnica más avanzada como los “contenedores” (generalmente denominados “contenedores de contexto” o “contenedores de aplicación”). ¿Te suena esto de algo? Si has leído y comprendido el apartado anterior sobre la Inyección de Dependencias apreciarás las similitudes con el “contenedor de inyección de dependencias”. En este caso el contenedor gestionará el ciclo de vida de nuestra aplicación, no la inyección de dependencias.
Y ya que estamos, ¿por qué no usamos el mismo contenedor para que se encargue de la inyección de dependencias y además de la inversión de control? Enhorabuena, empiezas a acercarte a las entrañas de frameworks como CDI y Spring.
Hoy en día tenemos IoC por todas partes: JSF, EJB, CDI, Spring framework. Incluso ciertos componentes definidos como API, como por ejemplo JPA (Java Persistence API) definen ciertas anotaciones como @PrePersist, @PostPersist, @PreRemove, @PostRemove, @PreUpdate o @PostUpdate que pueden ser incluíadas en métodos de nuestra aplicación para que el contenedor de persistencia los llame antes y después de realizar las operaciones de persistencia, borrado o actualización de datos.
Atando cabos sueltos (conclusiones)
¿Por qué se confunde la inversión de dependencias con la inyección de dependencias?
Primero porque coinciden en siglas, ambas son referidas habitualmente como DI, aunque es cierto que la inversión de dependencias, al ser un principio SOLID, es más habitual verla como DIP (Dependency Inversion Principle). De hecho en este post, para no liar más la madeja, he usado DIP para referirme a “Dependency Inversion Principle” y DI para “Dependency Injection”, pero no es extraño encontrarse por ahí las siglas DI refiriéndose simplemente a “Dependency Inversion”.
Y segundo porque suelen ser conceptos muy relacionados a día de hoy. Podemos usar el uno sin el otro, pero se ha demostrado que la inyección de dependencias es el mejor mecanismo que podemos usar para aplicar el principio de inversión de dependencias, y además es el mecanismo que implementan frameworks Java EE como CDI o Spring. Muchos desarrolladores trabajan con estos frameworks y están usando estos conceptos sin saberlo. Pero no hay que olvidar que son cosas distintas y que la inyección es un mecanismo que nos permite aplicar el principio de inversión de dependencias.
¿Por qué se confunde la inyección de dependencias con la inversión de control?
IoC es un concepto más genérico que la inyección de dependencias. DI es un tipo de IoC. La principal confusión, a mi entender, es que hoy en día los principales frameworks implementan ambos conceptos con el mismo contenedor. Tanto CDI como Spring tienen contenedores que asumen el control del ciclo de vida de los objetos (IoC) y además son capaces de inyectar dependencias (DI) que nos permiten a su vez aplicar el principio de inversión de las dependencias (DIP) en nuestra aplicación.
Y si a esto le sumamos que hay mucha información por la red donde aseguran que ambos conceptos son lo mismo (algunos de ellos de cierto prestigio) pues ya tenemos el debate servido.
Te recomiendo que le eches un vistazo a este artículo de Martin Fowler sobre la Inversión de Control y este otro donde compara IoC con la Inyección de Dependencias.




Deja un comentario